



Egy amerikai kutatásban azt vizsgálták, hogy a vezető LLM-modellek képesek-e szimulált orvos-beteg beszélgetésekben kideríteni minden szükséges információt a páciens állapotáról, és felállítani a helyes diagnózist.
A 2014-ben bemutatott Big Hero 6 animációs film tulajdonképpen egy AI egészségügyi asszisztens köré épül. A Baymax névre hallgató robot (nyitóképünkön) célja, hogy a főhős, Hiro Hamada egészségét maradéktalanul biztosítsa: így aztán képes észlelni, ha Hironak fáj valamije, kérdéseket tesz fel ezzel kapcsolatban, beépített szenzoraival kiegészíti a pácienstől szerzett információkat, ezek alapján felállít egy diagnózist, kezelési tervet dolgoz ki, sőt, még a kezelés utókövetését is elvégzi a betegnek feltett ellenőrző kérdésekkel.
Mindez nemcsak 2014-ben, hanem 2025-ben is csupán a filmvásznon válhat valóssággá: ez derül ki a lektorált orvosi folyóirat, a Nature Medicine oldalán év elején megjelent tanulmányból.
A kutatást neves amerikai egyetemek (mint a Harvard, a Stanford, a Northwestern) kutatói és egészségügyi intézmények szakemberei folytatták.
A valódi orvos-beteg párbeszédre még nem áll készen az AI
A 2023-ban lezárt kísérlet arra irányult, hogy az aktuális vezető nagy nyelvi modellek, az OpenAI GPT-3.5 és GPT-4 modelljei, a Meta Llama-2-7b modellje, valamint a Mistral AI Mistral-v2-7b modellje hogyan teljesít akkor, ha nem orvosi szakvizsgákat kell megoldani, hanem szimulált betegekkel való beszélgetések alapján kell diagnózist felállítani. Az összehasonlíthatóságot az is megkönnyítette, hogy a mintegy kétezer szimuláció főként azokon az eseteken alapult, amik az orvosi vizsgákban is szerepelnek.
Az eredmények alapján nagyon messze vagyunk még attól, hogy a mesterséges intelligencia átvehesse az orvosi feladatokat a rendelőkben. Az általánosságban legjobban teljesítő GPT-4 modell kitűnően szerepel akkor, ha megírt esettanulmányok alapján kell kiválasztani a helyes diagnózist tartalmazó választ a listából: 82 százalékban pontos választ adott ekkor a modell.
Ez 49 százalékra esett vissza akkor, amikor az AI-nak magának kellett választ adnia, és azt nem választhatta ki egy listából, és mindössze 26 százalékos volt a diagnózis pontossága akkor, amikor beszélgetést kellett folytatnia egy szimulált pácienssel.
Általánosságban a GPT-3.5 modell végzett a második helyen, míg a Llama-2-7b és a Mistral-v2-7b érték el a legrosszabb teljesítményt.
„A betegekkel való interakciók szimulálása lehetővé teszi az anamnézisfelvételi készségek értékelését, amely a klinikai gyakorlat kritikus eleme (…). A szimuláció a valós életben előforduló helyzeteket hoz elő, ahol a betegek nem feltétlenül tudják, hogy milyen információkat kell megosztaniuk, és csak akkor mondják el azokat, ha konkrét kérdéseket tesznek fel nekik” – magyarázta Shreya Johri, a Harvard Medical School doktoranduszjelöltje.
 A különbség zongorázható az előre megírt, minden szükséges információt tartalmazó esettanulmány és a szimulált orvos-beteg beszélgetés között, ahol a klinikai AI-nak kitartóan kérdezgetnie kell a részletes anamnézis és a diagnózis felállításához a beteget alakító másik AI-tól. A pácienst szimuláló AI egyébként az OpenAI GPT-4 modelljén alapult. Forrás: A Nature Medicine hasábjain megjelent kutatás
A különbség zongorázható az előre megírt, minden szükséges információt tartalmazó esettanulmány és a szimulált orvos-beteg beszélgetés között, ahol a klinikai AI-nak kitartóan kérdezgetnie kell a részletes anamnézis és a diagnózis felállításához a beteget alakító másik AI-tól. A pácienst szimuláló AI egyébként az OpenAI GPT-4 modelljén alapult. Forrás: A Nature Medicine hasábjain megjelent kutatás
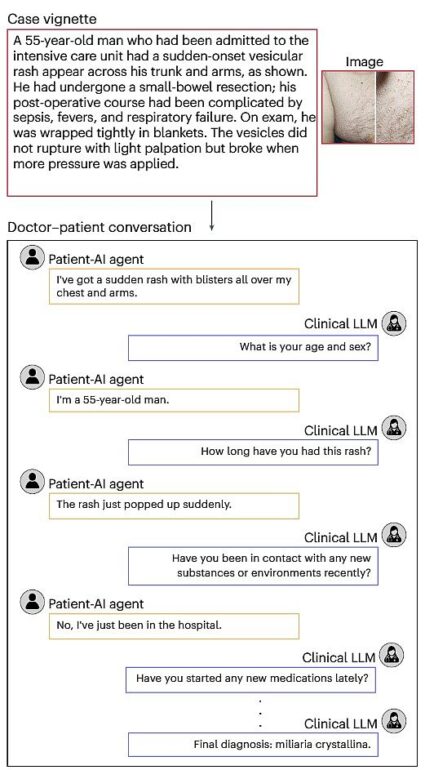 A különbség zongorázható az előre megírt, minden szükséges információt tartalmazó esettanulmány és a szimulált orvos-beteg beszélgetés között, ahol a klinikai AI-nak kitartóan kérdezgetnie kell a részletes anamnézis és a diagnózis felállításához a beteget alakító másik AI-tól. A pácienst szimuláló AI egyébként az OpenAI GPT-4 modelljén alapult. Forrás:
A különbség zongorázható az előre megírt, minden szükséges információt tartalmazó esettanulmány és a szimulált orvos-beteg beszélgetés között, ahol a klinikai AI-nak kitartóan kérdezgetnie kell a részletes anamnézis és a diagnózis felállításához a beteget alakító másik AI-tól. A pácienst szimuláló AI egyébként az OpenAI GPT-4 modelljén alapult. Forrás: A kutatók vizsgálták azt is, hogy hogyan teljesítenek a modellek az anamnézisfelvétel terén.
Ebben is a GPT-4 volt a legjobb: az OpenAI modellje a szimulált esetek 71 százalékában volt képes összeszedni maradéktalanul a releváns kórtörténetet. Azonban ha ez meg is történt, az sem volt garancia egyik modellnél sem a mindig pontos diagnózis megállapítására.
Ha nem is most, de később el fogja venni az AI az orvosok munkáját?
Ugyanakkor még ha el is jut odáig az AI-technológia, hogy képes legyen szimulációkban konzisztensen a kórtörténet hiánytalan felvételére és a helyes diagnózis felállítására, akkor sem fogja a mesterséges intelligencia elvenni a húsvér orvosok munkáját – fűzte hozzá Pranav Rajpurkar, a Harvard Medical School adjunktusa.
A valódi egészségügyi gyakorlat ugyanis sokkal bonyolultabb, mint ezek a szimulációk:
az orvosoknak a legtöbbször több beteget kell szimultán kezelniük, miközben koordinálnak más egészségügyi szakemberekkel, ráadásul a diagnózis felállítása együtt jár fizikai vizsgálatok elvégzésével és gyakran a páciens szocioökonómiai helyzetének megértésével is.
Ahogyan Rajpurkar összegezte: „Az AI hatékony eszköz lehet a klinikai munka támogatására – de nem feltétlenül helyettesíti a tapasztalt orvosok holisztikus ítélőképességét.”
Azt egyébként, hogy az healthtech merre tarthat 2025-ben Európában, ebben a cikkünkben jártuk körül.
NYITÓKÉP: Baymax, a Big Hero 6 AI egészségügyi asszisztense, amint meg szeretné tudni, hogy páciensének 1-től 10-ig terjedő skálán mekkora fájdalmai vannak.









